
试想一下,在一个平台上就能实现全球基因组数据的搜索和访问,是不是可以帮助研究人员轻松解决数据查找问题,从而提升基因组学研究的整体速度。
英国剑桥的Repositive就是这样一个免费的在线平台。Repositive集结了来自全球各地的基因数据资源,用户通过这个平台就可以实现数据资源的搜索和访问。
这样一个操作简单且轻松的平台,可以帮助研究人员更有效的寻找到可靠的数据信息,不仅能够帮助研究人员节省下大量数据挖掘的时间,还能帮助把这些数据的价值发挥到最大。
Repositive创始人兼CEO Fiona Nielsen毕业于南丹麦大学,曾是illumina的生物信息科学家,她认为精准医学的成功与否,实际上取决于数据信息的价值。因此,她认为Repositive所做的信息挖掘工作,将有可能改变基因组学研究的现状。
挑战:数据访问是主要瓶颈
在生物制药领域,无论是大型企业还是小公司,通过基因组学数据去评估药物风险和药物开发价值是必不可少的一步。这一步,基因组学数据是基础,这需要寻找到大量的基因组学数据集进行统计。如何获得及时且有效的数据资源,对这些公司来说非常重要。
然而,对基因组学数据研究人员来说,这些数据的查找和访问令人头疼的问题。全球领域开展了基因组学研究不计其数,一方面积累了丰富的数据资源,但另一方面,这些丰富的资源也给信息的查找带来了挑战:这些资源要如何访问?找到访问入口后要如何从海量的信息中查找到自己想要的信息?
无疑,在这样的模式下,信息查找是非常繁琐、费时的工作。
Nielsen从事过一些学术和商业研究工作,这种糟糕的经历她有过不少次。做了几年研究工作后她发现,基因组学临床解读的瓶颈其实并不在分析算法和设备上,而是缺少一个真正准确可靠的数据资源和查找方案。
2013年12月,Nielsen做了个决定,她从illumina辞职,成立了慈善机构DNAdigest。Repositive就是DNAdigest的一个产品,希望通过帮助科研人员轻松实现基因组学数据的查找和访问,以加速基因组学研究。
“我不是一个成功的科研人员。”Nielsen承认,“但我想我能做点其他的,让有能力的科研人员做的更好。”
解决方法:数据资源整合
很多人想知道,在这样一个数据资源整合平台建立之前,科研机构是如何实现资源访问的呢?现实中的科研工作并非像电影里那么炫酷,更多的是日复一日的试验,记录,重复。数据查找和访问更是份枯燥且繁琐的苦差。
事实上,目前各家数据资源的标准都不一样。而要使用这些数据,首先要做的就是资源整合,把各家标准统一,工作量非常大。其次,全球范围类的数据集合那么多,要挨个去查找是极其麻烦的。如果要把所有的数据库都扒一遍,即便是HGNC、OMIM以及Uniprot这些明星科研机构的科学家们,恐怕也得皱一皱眉。
这就造成了两个现象:一是数据查找和访问花费了研究人员大量的时间和精力;二是即使信息无处不在,但许多信息其实是被闲置的。
Repositive则可以一劳永逸的解决这些问题。通过Repositive,用户可获得多个知名的基因数据库的访问权限,这其中包括全球知名的数据库,比如1000人基因组计划和基因表达图谱(Genome Expression Atlas);还有爱沙尼亚生物中心、GenomeAsia100K这些鲜为人知的数据源;甚至还包括了InSilico DB 和 Xpressomics这样的企业数据。
目前,Repositive平台上已经集结了全球范围内超过100万个数据集,数据量每个月都在扩大。Nielsen透露,他们的目标不仅仅是公共的数据资源,同时还要把世界各地的大型数据库,科研机构、公司以及公益项目的数据也吸收进来。
据了解,Repositive已经与阿斯利康、默克以及未因生物等制药巨头和生物公司达成合作,将共同建立一个支持肿瘤研究的协同数据库。该项合作的目的是为从PDX模型到特定环境的肿瘤研究,提供数据发现和访问的入口。
精准医疗是最大受益方
通过这样一个数据平台,受益最大的就是精准医学领域。精准医学根据个人的遗传背景来寻找适合的治疗方法,对疾病基因层面的认识是基础。要从基因层面认识疾病,没有强大且可靠的基因组数据资源,是无法实现的。
除了惠及各地的基因组学研究人员,Repositive也将为数据提供方带来福利。通过Repositive,他们可以扩大自己数据资源的影响力,同时还能获得更多的资源,推进科研研究。
在保证患者和数据捐赠者权益的前提下,Repositive希望向更多的研究人员提供数据访问解决方案,以此将这些信息的价值最大化。
下一步,Repositive还希望像研究人员提供更多具有人口多样性特点的数据,以保证研究结果的准确性和全面性。截止到2016年,Repositive已累计获得融资1200万美元。
来源:动脉网 作者:周梦亚

为你推荐

 资讯
资讯 带状疱疹疫苗“遇冷”,百克生物2024年净利润腰斩
近日,国内疫苗龙头企业百克生物发布2024年年报,数据显示,其报告期内实现营收12 29亿元,同比下降32 64%;归属于上市公司股东的净利润2 32亿元,同比下降53 67%。对于营收...
2025-04-23 12:59





 资讯
资讯 重庆常用药联盟接续集采中选结果
近日,重庆常用药联盟接续集采中选情况公布,该联盟由重庆牵头,联合湖北、广西、海南、贵州、云南、青海、宁夏、新疆及新疆生产建设兵团等十省(区、市)开展的药品集中带量采...
2025-04-21 18:48

 资讯
资讯 全周期智控慢病,诺和诺德与京东健康开启战略合作
2025年4月21日,全球领先的生物制药公司诺和诺德与京东健康在北京正式签署战略合作协议,标志着双方在糖尿病和体重管理领域的合作进入新阶段。依托诺和诺德百年深耕慢病领域的专...
2025-04-21 15:57
 资讯
资讯 康方生物1类新药依若奇单抗上市申请获批,用于中重度斑块状银屑病成人患者
该药是我国第一个且唯一获批上市的IL-12 IL-23“双靶向”单克隆抗体新药,是康方生物自身免疫性疾病领域首个获批上市的一类新药。
2025-04-21 13:39
 资讯
资讯 阿斯利康乳腺癌1类创新药卡匹色替片中国获批
该药适用于联合氟维司群用于转移性阶段至少接受过一种内分泌治疗后疾病进展,或在辅助治疗期间或完成辅助治疗后12个月内复发的激素受体(HR)阳性、人表皮生长因子受体2(HER2)...
2025-04-21 11:02
 资讯
资讯 辉瑞宣布终止一款口服GLP-1减肥药的临床开发
近日,辉瑞在其官网宣布,决定终止开发口服胰高血糖素样肽-1受体(GLP-1R)激动剂Danuglipron(PF-06882961),原因系在一项有关用药剂量的临床试验中,一名患者出现了可能由该...
2025-04-21 10:29
 资讯
资讯 福建省医保局印发单列门诊统筹支付医保药品目录(2024年版)
根据2024年6月发布的《福建省医保药品单列门诊统筹支付管理办法(试行)》,为了让参保患者无需住院、在门诊就医也能用上国家谈判药品、享受医保待遇,将适用于门诊治疗、使用周...
2025-04-20 13:34
 资讯
资讯 首批中国消费名品名单,医药健康企业有哪些?
近日,工业和信息化部办公厅发布首批中国消费名品名单,分为中国消费名品名单和中国消费名品成长企业名单。首批中国消费名品名单共包括93个企业品牌和43个区域品牌。中国消费名...
2025-04-20 11:17
 资讯
资讯 携手共绘“个性化近视手术”新蓝图:爱尔眼科与爱尔康启动100家医院全光塑技术战略合作
双方将以技术共享为核心,以人才培养为支撑,以科研协作为纽带,全力推进屈光手术标准化诊疗体系建设,加速前沿技术在临床领域的普及应用
文/ 屈慧莹 2025-04-19 23:35
 资讯
资讯 CDE:简化港澳已上市传统口服中成药内地上市注册审批申报资料及技术要求
允许香港、澳门特区本地登记的生产企业持有,并经香港、澳门特区药品监督管理部门批准上市且在香港、澳门特区使用15年以上,生产过程符合药品生产质量管理规范(GMP)要求的传统...
2025-04-18 18:54
 资讯
资讯 君德医药完成近亿元A轮融资,加速推进创新药械组合平台建设与产品上市
本轮融资主要用于首个减重口服器械的注册及生产销售,以及加速多个核心创新药械组合技术平台的产品管线研发进程。
2025-04-18 14:34
 资讯
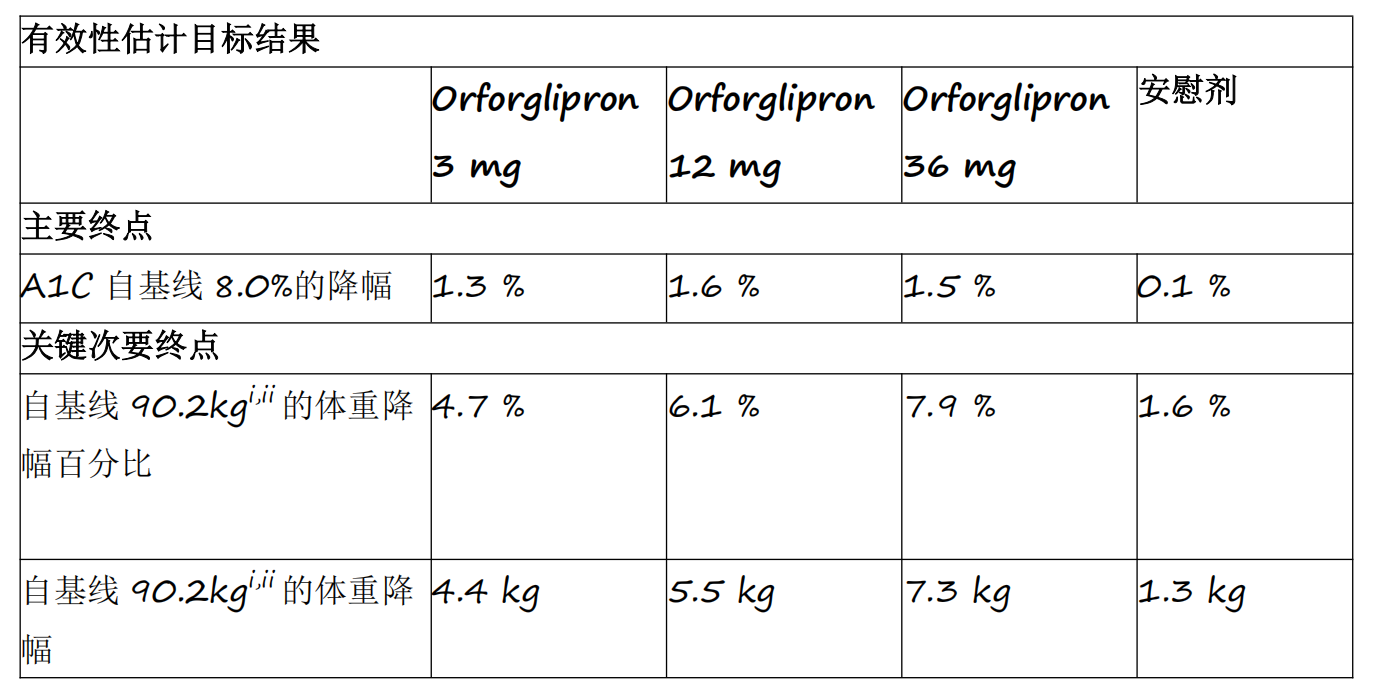
资讯 礼来首个小分子口服GLP-1RA药物orforglipron 3期临床研究成功
Orforglipron是首个成功完成3期临床研究的小分子GLP-1类药物,各剂量组平均A1C降幅为1 3%至1 6%
2025-04-18 14:12