
从微生物学专业到生物信息领域
生命是数字的,由遗传物质DNA上四个脱氧核糖核苷酸编码。形象一些表述,就像我们每天都在使用的电脑,电脑是数字的,最低层是由1和0这两个数字编码实现。解码遗传物质DNA上携带的信息,是一个长而曲折的科研奥德赛之旅。
我在南开大学攻读微生物学时,人类基因组计划已经启动,一代测序技术的低通量、低效率和高昂的价格,使得这一耗时长达十余年的项目看上去有些高不可攀,也限制了它在基因组学上的大规模应用。而上世纪80年代出现的基因芯片技术可以大规模、高通量地研究众多基因在各种生理、病理状态下的多态性及其表达变化。1998年基因芯片计划启动,记忆中,1999年,南开大学生命科学院院长从美国交流学习回来后很激动,为我们做了一场生物芯片的专题报告。专题报告使我深受感染,激发了我对高通量大数据分析研究的兴趣,在申请博士时,毅然选择了生物信息方向。
2002年,我获得英国达尔文基金会提供的全额奖学金到爱丁堡大学攻读博士学位。基金会提供的奖学金不仅使我可以专心科研,无生活的后顾之忧,并且在博士课题启动之前为我提供了3个月的生物信息专业培训,以弥补当时我在生物信息领域经验技术的不足。
我的博士课题,以及2008年我在伦敦大学国王学院所做的英国心脏基金会的项目,都主要专注于比较基因组学,大批量蛋白质三维结构预测,大规模蛋白质交互作用预测,和蛋白质组学分析,也就是说,主要集中在下游蛋白质层次上的研究。从预测结构出发,研究变异和功能结构之间的关系,以及蛋白质之间的相互作用,来理解疾病的发生机制,为药厂研发新药提供理论基础。
2005年底我博士毕业后,在爱丁堡大学信息学院人工智能研究中心做博士后。那时的我在加强信息计算方面的知识与能力的同时,开始把视线转向生物医学信息分析,通过项目合作在爱丁堡大学医学院接受了大量临床试验、医学统计、基因组、流行病学方面的知识,为我今时今日的工作打下了基础。
在这一系列的研究学习中,我意识到要深入了解疾病发生机制,还是先要从最基础的遗传物质开始,在基因组、转录组层次上去研究和理解遗传物质所携带的信息。2010年,我转入帝国理工大学,承担一项欧洲研究委员会的项目,主要应用Illumina的solexa平台和Roche的454平台,结合多种学科——分子系统发生学、群体遗传学和基因组学,在基因组和转录组水平来理解为什么同地域无地理隔绝情况新物种形成的机制,寻找与物种发生相关的基因。当时,我们所研究的物种,包括植物、鱼类、鸟,大多都是非模式生物,因此涉及到的NGS技术,也包含了从头测序策略设计、参考基因组和转录组组装、基因组转录组注释,到重测序策略设计、变异识别、RNA剪切和表达水平变化分析、功能挖掘等。在2013-2015年间,开始承担Syngenta、剑桥大学等一些公司和科研机构在NGS方面的生物信息咨询顾问工作,对NGS技术及其分析应用有了比较广泛深入的了解。2014年底,我加入为朔医学大数据,帮助搭建基于NGS的个体化医疗数据分析注释平台。
NGS技术的发展和疾病基因组学的发展
人类基因组学计划所产生的参考基因组是当今人类基因组学研究的基础。但参考基因组只是基于少数几个个体的基因型而组成。而DNA作为遗传物质,不但编码了物种间的差异,物种内不同个体之间的差异也包含其中。而这种差异绝大多数是非致病的、多态性的,但这类多态性差异在临床上也往往具有很大的影响。它可能影响个体对疾病的易感性,也可能影响个体对药物的敏感性或毒副作用,对药物的代谢能力,也可能影响个体治疗的预后效果。我们知道,与疾病发生相关的变异通常在人群中发生频率较低,要发现这些与疾病发生相关的罕见变异,经常需要千人规模的比对。对这些临床相关的非致病变异和致病变异的大规模研究,是一代低通量测序技术难以实现的。
二代高通量测序技术从2005年出现在市场后,就得到迅速的应用,不仅被大量用于非模式生物的基因组组装和功能研究,也被广泛用于人类基因组的重测序,来识别和筛选与疾病发生和治疗相关的基因和变异。以肿瘤为例,肿瘤的发生是一个多步骤、多基因突变的过程。一个典型的实体瘤含有30到70个突变,其中包含2到8个驱动基因突变。例外的如接受大量紫外线照射的黑色素瘤患者和吸烟肺癌患者,每个肿瘤可达到200个非同义突变,也就是所谓的热肿瘤。识别这些变异就可以帮助病人进行肿瘤的分子分型和准确用药。
用二代测序来识别肿瘤基因组中的变异也存在着很多挑战:健康组织的污染、DNA片段降解、肿瘤的异质性、肿瘤基因组变异的多样性等都需要在分析时针对肿瘤的特征进行相应的调整。有时甚至需要对肿瘤基因组进行重新组装来正确地识别大片段结构变异。
搭建优质的生物医学数据库,意义深远
高通量测序技术发展至今,它在临床研究上的巨大价值已经被充分证明。但二代测序的数据量大,即使由专业的生物信息人员分析,分析结果对临床医生来说仍然如同天书,需要与临床对接结构化的精细数据库做临床解读。
这就需要我们不仅做NGS测序和数据分析,同时需将基因信息与临床对接,搭建优质的个体医疗数据库,包含疾病基因组学、药物基因组学、基因变异数据库、治疗回访数据库。从PubMed、COSMIC,NCCN指南,FDA,ClinicalTrial,DrugBank等多个数据库中,我们由专业团队人工教验收集,有严格的收录质控标准和流程,经多方审核,可以说是最精细、最结构化的高效对接临床,对分析结果出具临床解读报告。
我们研发的iCMDB已被新加坡健康科学局授予医疗器械级别的资质—— ISO13485资质认证。目前已被国内解放军307医院、301医院、人民医院、同仁医院、武汉同济医院血液科等,国外新加坡中央医院、新加坡国立医院、美国西奈山医院、泰国Ramathibodi医院等接受或进行合作。目前数据库包括多种实体瘤、血液癌症、线粒体基因病、传染病、孟德尔式遗传病、疾病风险预测,以及150种药物的药物基因组学数据,包括化疗、放疗、靶向治疗方案、激素治疗、细胞免疫治疗、疾病进展监控及预后分析、抗药性分析。
由NGS带动的个体化精准医疗的发展,确确实实为许多患者带来了希望。我所知道的一位非小细胞肺癌患者,患病快十年了,刚开始做基因测序,根据测到的变异找到了相应的靶向药,效果非常好。一两年后产生了耐药性,再次的基因检测发现患者DNA上新发生的变异,幸运的是刚好靶向新变异的药得到批准,患者买到新药服用后效果很好,肿瘤再次得到了控制。临床应用的实力,使我们更加有信心和动力去完善和推广我们自己的平台,为广大患者医疗和生活质量的提高做力所能及的贡献。
未来,生物医学大数据在个体化医疗中的应用会更加广泛, Vishuo团队也将为科学研究项目提供适合的数据分析与解决方案,最大程度的提升病患的生存预期与生存质量。
医谷链
《Vishuo医疗郭栋梁:未来精准医疗数据库领域只有五到六家公司能生存下来》
《田埂:我与NGS这十年,前五年拼命学技术,后五年推广应用》
《药明康德高级副总裁茅矛:NGS十年,肿瘤分子诊断,我一直在走的路》
《上海立迪生物闻丹忆,NGS十年,基因测序在药厂里的那些事儿》
来源:测序中国(微信号:seq114) 作者:全雪萍

为你推荐
 资讯
资讯 悦唯医疗完成近亿元A++轮投资,加速重症冠心病诊疗全流程创新器械研发与国产替代
此次融资将主要用于深化冠心病诊疗全流程创新器械和脉动式左心室辅助系统等新产品的研发,以及加速已获准上市的心脏稳定器等产品的市场推广。
2025-04-03 09:28
 资讯
资讯 海尔盈康一生启动孤独症儿童关爱行动,创新罕见病可持续公益新生态
本次活动聚焦孤独症儿童的诊疗,探讨交流AI赋能全流程防治康体系创新、前沿性生物科技诊疗技术等话题,旨在通过生态联盟的力量推动医学研究、科技创新与人文关怀的融合,让“星...
2025-04-03 09:11

 资讯
资讯 《NPJ digital medicine》刊发李冬梅教授团队成果:AI赋能高效识别眼睑肿物
亚太眼整形外科学会主席、中华医学会眼科分会眼整形眼眶病学组副组长李冬梅教授团队携手爱尔数字眼科研究所,在《NPJ digital medicine》(影响因子:12 4)学术期刊发表团队...
文/李林 2025-04-02 10:27

 资讯
资讯 默克全球执行副总裁周虹:合作与创新是默克未来五年战略的两大关键词
近日,德国默克医药健康全球执行副总裁、中国及国际市场负责人周虹带领医药健康中国及国际市场管理团队开启了2025年度首次“中国行”。
2025-04-01 17:11
 资讯
资讯 首个且唯一,阿斯利康PD-L1单抗获FDA批准治疗肌层浸润性膀胱癌
度伐利尤单抗联合吉西他滨和顺铂作为新辅助治疗,随后度伐利尤单抗作为根治性膀胱切除术后的辅助单药治疗,用于治疗肌层浸润性膀胱癌成年患者。
2025-04-01 14:37
 资讯
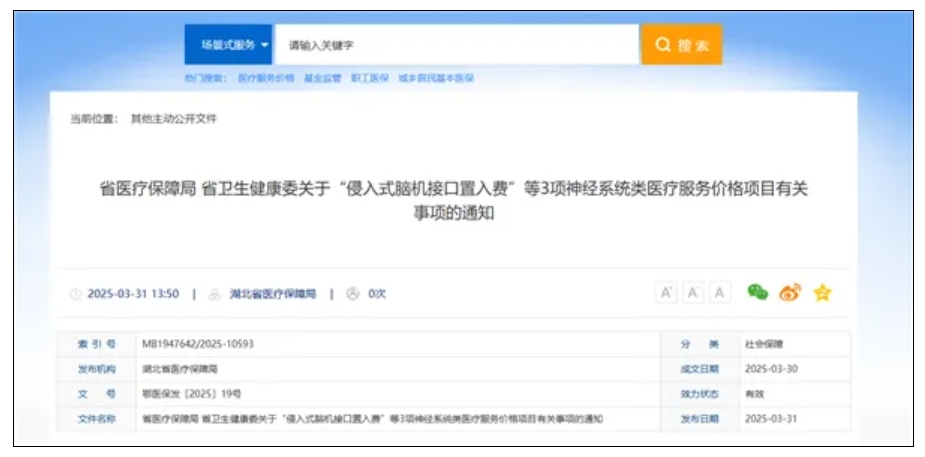
资讯 全国首个,湖北为脑机接口医疗服务定价
昨日(3月31日),据“湖北发布”消息,湖北省医保局发布全国首个脑机接口医疗服务价格,其中,侵入式脑机接口置入费6552元 次,侵入式脑机接口取出费3139元 次,非侵入式脑机...
2025-04-01 11:03
 资讯
资讯 一款国产创新流感药,获批
近日,据国家药监局官网信息显示,青峰医药下属子公司江西科睿药自主研发的1类创新药玛舒拉沙韦片(商品名:伊速达)正式获批上市,用于既往健康的12岁及以上青少年和成人单纯性...
2025-04-01 10:22
 资讯
资讯 26省联盟药品集采启动,聚焦妇科用药和造影剂
近日,山西省药械集中招标采购中心发布《关于做好二十六省联盟药品集中带量采购品种数据填报工作的通知》,开展相关采购数据填报工作。
2025-03-31 21:48
 资讯
资讯 优时比罗泽利昔珠单抗注射液(优迪革)中国获批,全球首个且唯一双亚型创新药治疗全身型重症肌无力
作为唯一人源化、高亲和力且具备创新修饰结构的IgG4单抗,关键Ⅲ期MycarinG试验证实罗泽利昔珠单抗注射液(优迪革®)较安慰剂显著改善全身型重症肌无力患者的多个临床终点与结局。
2025-03-31 15:58
 资讯
资讯 从手术麻醉到生命全周期护航,麻醉学科发展拓宽生命边界
3月26日,由中华医学会麻醉学分会、中国医师协会麻醉学医师分会等23家学协会共同举办的2025年中国麻醉周学术活动的启动仪式举办,该活动以“生命之重,大医精诚——守生命保驾护...
2025-03-31 15:30
 资讯
资讯 欧狄沃联合逸沃成为中国目前唯一获批的肝细胞癌一线双免疫联合疗法
欧狄沃联合逸沃对比仑伐替尼或索拉非尼,可显著改善不可切除肝细胞癌一线患者的总生存期(OS),客观缓解率(ORR)可改善近3倍,中位缓解持续时间(mDOR)达30个月
2025-03-31 13:45
 资讯
资讯 罗氏制药榜首 “现金牛” 产品罗可适(奥瑞利珠单抗)在华获批:开启多发性硬化症一年两次治疗新时代
罗氏制药今日(3月31日)宣布,其旗下创新药罗可适®(Ocrevus®,通用名:奥瑞利珠单抗注射液 ocrelizumab injection)正式获得中国国家药品监督管理局批准,每六个月静脉输...
2025-03-31 13:39
 资讯
资讯 三生有幸,医者仁心:三生制药向全体医药工作者致敬!
3月30日是国际医师节,由三生制药公益支持的以“三生有幸,医者仁心”为主题的公益活动,携手20位医生代表,以寄语海报的形式,共同向全体医护人员表达诚挚的祝福与关爱。
2025-03-30 17:38
 资讯
资讯 新版药典自2025年10月1日起实施
3月25日,国家药监局官网发布《国家药监局 国家卫生健康委关于颁布2025年版的公告(2025年第29号)》,2025年版《中国药典》自2025年10月1日起施行。
2025-03-30 17:07