
伴随着精准医疗的提出,本已热门的遗传基因检测被越来越多的人提及并关注。自2003年第一个人类基因被测序后(当时花费为30亿美元),由于技术的更新,费用的降低,和基因相关的检测技术及服务开始大量涌现。现如今,已经有上千种的疾病使用到了遗传基因检测( Centers for Disease Control and Prevention,2015)。目前已登记有26,000个实验室检测项目涵盖了5,400种状况和3,700种基因 (NCBI,2015)。而一个全基因组测序只需6995美元(Skirton, Jackson, Goldsmith, & Connor,2013),专门针对个体消费者的遗传基因检测只需99美元。一份由United Health Group发布的市场报告(UnitedHealth,2012)显示,遗传基因检测是实验室检测市场中发展最快的一分支,全美在此上的开支为50亿美元,预计到2021年,可达到150亿至250亿美元。面对这热火朝天的场面,究竟什么是遗传基因检测?有哪些不同种类,能对健康治疗起什么帮助作用?数据分析在其中的角色是什么?在全民参与健康保险的变革时代,美国保险业对遗传基因检测又是怎么对待?现阶段,大众又是如何看待此类检测的?本文作者陈氏夫妇为生物医药大数据分析行业的顶尖专业人士,在美国从事相关的理论模型构建与实战研究多年,现在从专业角度对此相关概念进行阐述,即使资本市场对此概念火热追捧,但也没有多少人真正明了这些基本理论和实际的应用。不过期望能促进有兴趣者对此深入了解,更希望抛砖引玉,能有更多的专业人士进一步阐述和探讨,也就达到目的了。
一、什么是遗传基因检测
遗传基因检测(genetic and genomictesting)是使用实验室方法来看从你父母那儿遗传得来的DNA指令:即你的基因。它可以用来确定健康问题上增加的风险,选择治疗,或者评估对治疗的反应。
遗传检测(Genetic testing)通常使用于遗传性疾病方面,用以检测某些与特定疾病发生相关联的基因(易感基因),进而判断患上此疾病的风险系数。比如,众所周知,一个变异的BRCA1或 BRCA2基因的存在,会增加本人得乳腺癌或卵巢癌的风险。而基因检测(Genomic testing)通常只涉及到癌症肿瘤本身。它主要用于给病患和医生提供关于某个特定癌症肿瘤的具体信息:比如,对于某些肿瘤需要加大治疗力度;而对于“表现温和”的肿瘤,可以选择比较温和妥当的治疗方式。进而还引出了两个热词,肿瘤靶向治疗和个体化治疗,乔布斯患有胰腺癌(恶性程度最高的一种癌症)就是综合采用了各种方法,延续了9年生命,并且生活质量较好。
本文采用的定义是前者,即遗传检测,但基因是检测中的一个必不可少的组成部分,所以笼统称为遗传基因检测(genetic and genomictest),但不牵扯后者的定义和内容。
二、遗传基因检测的种类和效用
那么,现在究竟有哪些类型的遗传基因检测?它们各自的服务目的又是什么?美国国家人类基因研究所提供了7类现已比较普遍的检测及定义。
诊断检测:用来精确判定导致个体生病的疾病。诊断检测的结果可以帮助个体及时做出如何治疗或管理健康的选择。
预测和症状发生前的遗传基因检测:用来发现可能增加个体患病几率的基因变化。这些检测的结果可用于对个体患上某种特定疾病的风险预测,从而可能对个体的生活方式及健康保健的调整有所帮助。
载体检测:用来发现携带有和疾病相关的易感基因的个体。载体本身可能没有任何疾病的显状。但,他们具有把易感基因遗传到下一代的能力。下一代就有可能出现疾病或成为新的载体。有些疾病产生需要的易感基因是必须从父母双方那儿遗传下去的。这种类型的检测对有遗传疾病家族史的个体尤为重要,因为他们对特定的遗传疾病往往有着比正常人更高的风险。
产前检查:用来帮助识别在怀孕期间胎儿是否有某些严重的疾病。
新生儿筛查:用来检查发现出生一到二天的新生儿是否患有会影响健康和今后发展的已知疾病。
药物基因组学检测:用来提供关于特定药物在人体内如何产生作用的信息。这种检测能帮助个体的医疗保健人员根据你的基因构成,选择效果最好的药物。
研究性遗传基因检测:用来更多地了解基因对健康和疾病的贡献。此类研究的结果可能不直接有益于参与者,但它们可以帮助研究人员更好的理解人体,健康和疾病,从而推动医学及健康科学的进步,在今后使他人受益。
三、遗传基因检测是否包查百病?
虽然已有成千上万涵盖了几百种人类疾病和性状的相关联基因被发现,但对于大多数疾病而言,仅仅只有很小一部分的遗传基因被识别出来,更何况,相关联并不表明该基因就是引起疾病的罪魁祸首,即关联性不等同于因果性。
因此,几乎所有复杂的疾病,迄今为止,即使是已知的具有高度遗传性的疾病,现有的遗传基因风险分析往往只能部分解释疾病的发生(Do C.,, et al.,2012)。比如,对于10种复杂疾病(阿尔茨海默病,双相性精神障碍,乳腺癌,冠状动脉疾病,克罗恩病,前列腺癌,精神分裂症,系统性红斑狼疮,1型糖尿病,2型糖尿病)的发生,只有约0.4%到31.2%是被已知的易变基因变种所解释了的 (So HC., et al.,2011)。这说明仅凭我们现在已发现的基因,对这些包含遗传因素的疾病的产生进行预测是很不完善的。也就是说,大多数情况下依托单核苷酸多态性(SNP)(可笼统理解为一种DNA基因变异)建立的风险预测模型对于现有已知标记(染色体上一个可以被识别的区域)只能获得较差的预测值(DoC.,et al., 2012)。
因此,在临床上,人们对于使用遗传基因进行疾病的风险预测十分谨慎。此外,基因组学涉及的不仅仅只有基因方面的影响,还有环境方面的影响,也包括了更复杂的基因与基因,基因与环境之间的交互影响等等,从而增加了收集数据并依此建模的复杂性。
四、遗传基因检测里的数据分析
上面提到,使用基因信息所得到的风险预测模型并不理想。那么怎么判断预测模型的好坏呢?这儿就有必要了解一下全基因组关联研究(GWAS)具体是怎么回事和数据分析是如何应用在里面的。全基因组关联研究又称为常见变种相关性研究(common-variant association study:
CVAS)。它是一种针对个体的许多常见共同基因变种的检查,用以判别是否有任何变种与某一性状(比如疾病表现特征)相关联。GWAS通常侧重于研究单核苷酸多态性(SNPs)和一些有性状的主要疾病的关联性。最常见的此类研究方法称为表型检测,即把参与者根据他们的临床表现特征分成两组,比如患者组和健康人口组,然后分别检测并比较他们的SNP。如果某一类型的变种(等位基因)或多或少经常出现在患者组中并被统计验证它出现不是偶然的,该SNP就被认为和此疾病是相关联的。该相关性SNP所标识的人类基因组某一区域就被认为会影响患病的风险。此处再强调一下,相关性不等同于因果性。
通过GWAS研究所发现的与特定疾病有关联性的SNP并不能被认为就会引起或增加患病的风险。而依据基因的风险预测模型就是根据SNP和疾病相关的强弱程度计算出个体患病风险系数,并在此系数基础上进一步将个体划分入不同患病风险的组别。预测判断精准与否直接影响到个体是被正确划入风险高的组别还是风险低的组别。
最常用的一个判别风险划分精准度的指标,原本是应用在信号检测理论中的叫做:接收者操作特征曲线,receiveroperatingcharacteristiccurve,缩写为ROC。曲线下的面积称为Area undercurve,缩写为AUC。这两者我们综合起来用于判别风险划分精准度。由于事实上,几乎没有什么预测模型是完美的,因此人们需要计算这个预测模型划分的正确率和错误率。相应的,在此我们来介绍一下四个基本概念:
真实高风险,虚假高风险,虚假低风险,和真实低风险,见图一。在我们知道最后个体患病结果的情况下,通过模型预测分类后估计的风险及非风险个体数量。
图一:

真实风险是真实高风险和真实低风险的总和,也就是归类归对了,被划分为高风险的个人的确患病了,而被划为低风险的人没有得病。虚假风险则是虚假高风险和虚假低风险的总和,即归类归错了。我们通过图二来演示。从左到右,分类标准从十分保守趋向十分激进。左一的小图所设的分类标准要求超高的预测值才能被划入高风险组,从而造就了许多虚假的低风险(即许多被判定为低风险的人最终得病了)。而在右一的小图中,较低的风险预测值就可以被划分为高风险组,从而造就了许多虚假高风险。由此可见,选择分类标准极大地影响了预测模型的最终分类错误率。
图二:

好的分类标准当然是要有尽可能多的真实高风险数量和真实低风险数量,和尽可能少的虚假高风险数量和虚假低风险数量。一般而言,“激进”与否往往取决于个人被归类后,虚假高风险和虚假低风险,哪个会对其造成更严重的医疗健康后果。我们一般通过4个比率来体现一个分类标准的正确率和错误率,如图三和下面的公式所示(后面保险业对遗传基因检测的态度和此有很大关系,所以这儿有必要简单介绍一下):
图三(深色范围是分子,深色+浅色范围是分母):


我们希望这些比率的情况是:真实风险比率越高越好,虚假风险比率越小越好,真实风险预测比率越高越好,虚假风险预测比率越小越好。他们数值的范围都是从0到1,但真实风险比率和真实风险预测比率是1最好。虚假风险比率和虚假风险预测比率是0最好。
接收者操作特征曲线(receiver 。
operating characteristic: ROC)正是体现了真实风险比率与虚假风险比率之间的动态关系,而线下面积(Area undercurve:AUC)则代表了一个风险预测模型综合预测能力。那么如何从真实风险比率与虚假风险比率得到接收者操作特征曲线呢?我们可以把模型计算得到的个体患病风险系数按照不同的分类标准进行划分归类,对应每一个分类标准可以得到一个2乘2的归类表格。例如,如果我们如果考查20个不同的分类标准(从保守到激进),就能得到了20个2乘2的归类表格。对应每一个表格可以算出相应的真实风险比率与虚假风险比率。将两者由低到高排序后以虚假风险比率为X轴,以真实风险比率为Y轴数值画成的曲线就是接收者操作特征曲线(ROC)。图四显示了若干ROC曲线,有好的,有不理想的。
图四:

那么如何解读接收者操作特征曲线呢?
首先我们注意到有一条从(0,0)到(1,1)的对角线,把图示的方块分成了一上一下两个三角形。任何落在方块下半部的那个三角形区域的ROC曲线是没有意义的,因为那个贯穿(0,0)和(1,1)点的对角线代表的是我们随机预测所会得到的ROC曲线,也就是说,如果我们什么模型都不要,靠随机翻硬币来决定一个个体是高风险的还是低风险的,那样翻上一万个人,我们得到的ROC曲线就会是那条对角线(真实高风险率和虚假高风险率是一半一半)。显而易见,那种靠翻硬币的预测模型是十分不靠谱的,而ROC曲线如果落在那条对角线之下,说明这个预测模型比翻硬币模型还要糟糕,自然是没有用的。图中的红色ROC曲线代表了一个十分优秀的预测模型,它表示这个模型的分类预测结果相当好。这是怎么看出来的呢?主要就是看AUC,即ROC曲线下的区域面积。这个面积越接近于1(1是这个方块的面积,也是AUC可能达到的最大值),ROC所代表的预测模型综合预测能力越强。这就是为什么我们称(0,1)这个角落为好角落,因为ROC曲线越贴近这个角落就越理想。但是单凭AUC还是不够的,我们还要看是否能在曲线上找到一个点有着足够高的真实高风险比率和足够低的虚假高风险比率,这个点所代表的分类标准就是最佳分类标准。(题外话:还有其他有效的衡量预测模型好坏的标准,本文就不赘述了。今后有机会,会在其他文章或讲座中提到)。
运用这些基本概念,现有的研究学术文章已经发表了根据AUC来判断SNP为基础的风险预测模型的精准程度了。研究结果表明使用SNP为基础的基因风险预测模型只在罕见的疾病类型中有着相对较好的预测能力,而在常见的疾病类型中的预测能力则差强人意。(DoC., etal., 2012)。这儿需要指出所谓好的预测能力也是相对的,因为不管在哪种疾病类型中,单纯的以SNP为基础的基因风险预测模型所获得的AUC值都不是很理想(小于0.8)。一般我们认为0.8-0.9是良好,0.9-1是优秀。
1.遗传基因检测的保险业状况
美国的医疗服务费用体系是以保险业为主要框架结构的。在美国,私有医疗保险业务几乎覆盖了全美三分之二的人口。医疗保健支付者针对这些医疗服务,必须对何时以及如何支付做出决策以平衡控制不断增加的健保费用,同时,又能保证健保质量的最优化。
美国一家名为DNA Direct公司针对206家拥有50,000会员以上的医疗保险公司进行了一项市场调查。有66家对外公开了他们的保险条例,其中有65家(98%)对遗传基因检测提供了保险服务。他们具体的保险范围如下:

这儿可以看到,所有的保险公司都没有把“直接面对消费者的基因检测”和“基因治疗”纳入到保险范围中去。这样的现象有其背后的复杂原因。保险业在制定保险条例时,制定者通常都是在有了充足证据的前提下开设保险业务的。2004年,美国疾病控制和预防中心(Centers 。
for Disease Control and Prevention: CDC)针对如何评估遗传基因检测的安全性和有效性制定了一系列的标准(ACCE) (Centers for Disease Control andPrevention, 2015):
·分析有效性(Analytic 。
validity):对感兴趣的基因检测究竟有多准确和可靠(比如前面提到的PPV,AUC标准等)。
·临床有效性(Clinical 。
validity):用于检测或预测结果的方法的稳定性和准确性有多大(是否不同时间,同一检测方法给出的结果变动会很大?)。
·临床实用性(Clinical 。
utility):有多大的可能,此检测能显着提高改善病人的状况。
·相关的伦理,法律和社会影响(Ethical,legal and socialimplications):此检测可能引发的一系列伦理,法律和社会影响。
针对于这四个标准,他们设计了44个问题来具体衡量各类遗传基因检测是否达到要求。感兴趣的读者可自行去此网站(http://www.cdc.gov/genomics/gtesting/ACCE/acce_proj.htm)查看细节。基因疗法现在还处于摸索研究阶段,还没有能完全达到并符合以上提到的所有标准。而直接面向消费者的基因检测服务,也面临类似同样的问题。好多基于全基因组关联研究的这些测试由于缺乏临床实用性而不能在临床实践中被推荐使用(RobsonME,et al., 2010) 。
。这里举一个来自23andMe(一家直接提供给消费者基因检测的大公司)的例子:一个消费者拿到的检测报告显示他在45到78岁之间患上冠状动脉疾病的风险是46.3%,而普通人的风险是46.8%。0.5%的差异在临床上几乎没有任何指导意义。相对于此,通过家庭病史的风险预测模型(另外一种风险预测模型,后文会提及),考虑到体重指数,生活方式的选择,胆固醇和血脂水平等的信息,此消费者反而能获得更多有指导意义的帮助(SkirtonH.,et al., 2013)。以上这些至少可以部分解释为何保险业对此两项基因检测服务不愿意进行投保服务。
2.公众对遗传基因检测的态度
普遍来说,公众对于遗传基因研究和新的基因技术是持积极态度的。虽然大多数人并不十分了解概率是如何被应用在遗传基因风险分类及预测上的,对遗传医疗保健专业人士所使用的技术语言也知之不详,但这不妨碍他们高度关注遗传基因检测(Condit 。
C,2010)。然而,这种积极态度是复杂的,并且因不同的基因研究,试验的用途,检验的临床效用,和遗传研究的应用领域(比如医疗领域相对于克隆领域)而有所不同。
一项研究显示公众态度对于“直接提供给消费者基因检测”的服务是相当积极的,但是真正决定去使用的却并不多(McBrideC.,et al.,2010)。除了以上提到的保险因素(即保险公司一分也不付,费用全得消费者自己掏腰包),公众对私人公司提供的此类服务并不十分信任。这种不信任主要存在于两方面,首先是对私人公司能否保证个人医疗信息的私密性存疑,其次是对通过私人公司获取检测结果的遗传咨询是否纯粹(不带有支持公司盈利的倾向性)有所顾虑。因此即使要做检测,公众也更有可能使用医生推荐的“直接提供给消费者基因检测”的服务而不是自己去找私人公司。(CritchleyC., et al., 。
2014)。此外,遗传基因检测后续是否存在临床治疗方法(临床实用性)也在很大程度上影响着人们是否要使用此检测的决定。比如,存在可能治疗方法的遗传性乳腺癌和结肠癌做的遗传基因检测比例要高于目前没有可能治疗措施的亨廷顿氏舞蹈症(CameronL,Muller C, 。
2009)。然而,有意思的是,人们在新生儿筛查上对临床实用性却又不那么看重了,就算所能检测的疾病不存在有效的后续治疗方法,父母仍对使用遗传基因检测有着相当大的兴趣(EtchegaryH., et al., 。
2012)。这可能是因为父母可以从新生儿筛查提供的基因信息上预先对孩子的出生及后面培养上可能出现的障碍做好心理准备,或者,他们可以用此信息来帮助今后的生育决定(EtchegaryH.,et al., 2012)。
尽管各种各样的遗传基因检测给人们提供了对相当多疾病的风险预测评估,但是,科学研究没有发现人们在获得此类信息后对他们的健康行为有所改变。一项针对“直接提供给消费者基因检测”的研究显示,大部分使用过此服务的受访者说,他们并没有由于检测的结果而改变他们的生活方式或者健康管理(McGowanM., et al., 2010)。一份针对5个临床实验的研究也表明DNA风险信息的提供无论对短期吸烟行为(小于6个月)的改变还是长期吸烟行为(大于6个月)的改变均无影响。目前,在获得了遗传基因检测结果后,人们唯一有所改变的行为是:当他们获取关于罕见基因突变相关的个人基因信息后,会去进行进一步的疾病检查,特别是具有遗传特性的癌症类疾病(SchneiderK, Schmidtke J, 2014)。
综上所述,尽管遗传基因检测的风险信息可以作为健康行为改变的一条引线,它似乎并没有能单独对健康行为的改变及维持提供足够的动力。当然,众所周知,改变有害健康或某些不利健康的行为是非常困难的。个人往往需要更有针对性的健康指导,结合健康理念和外界环境的改变,在适度经济刺激的推动下才能长期摈弃不良健康习惯。感兴趣的读者可参见以前本文作者写的《可穿戴设备及其数据利用的再思考》。
3.家族病史风险预测模型
相对于以研究基因相关性为基础的风险预测模型,还有一种更早被广泛应用在疾病风险预测上的模型:家族病史风险预测模型。2002年,美国疾病控制和预防中心(CDC)在确认家族病史是一个十分有效预测风险分类的工具但没有得到充分利用的原则基础上,推出了家族病史的公共卫生研究行动(OrlandoLA,et al.,2013)。家庭成员共享基因,行为,生活方式和环境。所有这些综合在一起可能影响他们的健康和慢性疾病的风险。大多数人有一些慢性的家族健康史疾病(如,癌症,冠状动脉心脏疾病,以及糖尿病)和异常健康状况(如,高血压和高胆固醇血症)。如果血缘关系较近的家庭成员中有人患有慢性疾病,那么他/她本人会出现此类疾病的风险较高。而且,家族病史信息可能有助于揭示还未被发现的基因因素及环境对疾病的影响。家族病史评估已经被证实能用于鉴别常见慢性疾病的高风险人群。例如,研究显示,在心血管疾病风险评估上,通过使用收集到的家族病史资料,对高风险个体的鉴别能力提高了40%(Qureshi N., et al., 2009)。当然,家族病史风险预测模型也有其不足之处。它和基因风险预测模型正好相反,在常见的疾病类型中发挥出相对较好的风险预测效果,而在罕见的疾病类型中它的预测能力就不很理想了(Do 。
C., etal., 2012)。
综上所述,家庭病史风险预测模型和基因风险预测模型在罕见或常见疾病中各有优势。他们互为补充。人们因而提出如果把这两种方法的结果结合起来,或者把基因信息和家庭病史同时利用起来建立新的风险预测模型将有助于我们更好地对疾病风险进行预测。这个研究方向目前还在探索实验阶段。
4.展望未来
回到本文开篇提到的精准医疗。精准医疗其实并不是一个新的概念,但在近期十分受关注,因为计算工具和更好的大型生物数据库的发展,使得循证精准医学的研究变得真正可行了。
针对这一理念,美国国立卫生研究院在2015年4月20号发布了一项通告,寻求100万公众对相关研究的参与支持,并承诺收集到的数据将作为研究资源用于开发和验证新的方法以改善健康。比如,发展根据个体差异的临床实践,定制诊断,预防和治疗策略。参与者将被要求提供生物标本(可能包括:细胞群,蛋白质,代谢物,RNA和DNA的全基因组测序),以及行为和环境数据。这些都将与他们的电子健康记录(电子病历)相连接。参与者医疗信息的私密性将被严格保护。
如此大规模的研究可以最大限度地发挥其研究的价值,包括:1)大量的参与者数量不仅保证了常见疾病能有充足的研究数据,即使是以往受限于人数及信息的罕见疾病,在这种收集方式下也能得到合理的研究数据用于推进更深层次的研究;2)以往采样人群中由于样本量太小而不具有研究代表性的特别人群,这次也可以获得足够数据来研究这些特殊人群与一般人群不同的健康差异性;3)收集涵盖了广泛的年龄范围,提供从婴儿到老年疾病的所有信息; 4)提供了广泛的遗传背景和环境因素的信息;5)大量的临床和实验室信息,并不限于任何单一疾病,还包括了患者自己报告的结果;6)直接使用移动设备和可穿戴式传感器收集到的大量参与者饮食,生活习惯,生活环境等相关信息;等等(NIH,2015)。
由此可见,借着大数据技术及算法蓬勃发展的东风,基因检测已经进入了一个风云际会的时代。综合利用基因检测结果,家庭健康史,个体饮食,生活,运动,环境等信息,通过大量数据进一步建立更为个人化的健康风险预测模型,将对整个人类社会无论是个体健康,商业经济,还是环境改变等等领域产生广泛而深远的影响。在未来的时间片段里,这是否是一个支点,可以翘起整个地球?
来源:贝壳社 作者:陈遵秋 陈漪伊 贝壳社

为你推荐
 资讯
资讯 悦唯医疗完成近亿元A++轮投资,加速重症冠心病诊疗全流程创新器械研发与国产替代
此次融资将主要用于深化冠心病诊疗全流程创新器械和脉动式左心室辅助系统等新产品的研发,以及加速已获准上市的心脏稳定器等产品的市场推广。
2025-04-03 09:28
 资讯
资讯 海尔盈康一生启动孤独症儿童关爱行动,创新罕见病可持续公益新生态
本次活动聚焦孤独症儿童的诊疗,探讨交流AI赋能全流程防治康体系创新、前沿性生物科技诊疗技术等话题,旨在通过生态联盟的力量推动医学研究、科技创新与人文关怀的融合,让“星...
2025-04-03 09:11

 资讯
资讯 《NPJ digital medicine》刊发李冬梅教授团队成果:AI赋能高效识别眼睑肿物
亚太眼整形外科学会主席、中华医学会眼科分会眼整形眼眶病学组副组长李冬梅教授团队携手爱尔数字眼科研究所,在《NPJ digital medicine》(影响因子:12 4)学术期刊发表团队...
文/李林 2025-04-02 10:27

 资讯
资讯 默克全球执行副总裁周虹:合作与创新是默克未来五年战略的两大关键词
近日,德国默克医药健康全球执行副总裁、中国及国际市场负责人周虹带领医药健康中国及国际市场管理团队开启了2025年度首次“中国行”。
2025-04-01 17:11
 资讯
资讯 首个且唯一,阿斯利康PD-L1单抗获FDA批准治疗肌层浸润性膀胱癌
度伐利尤单抗联合吉西他滨和顺铂作为新辅助治疗,随后度伐利尤单抗作为根治性膀胱切除术后的辅助单药治疗,用于治疗肌层浸润性膀胱癌成年患者。
2025-04-01 14:37
 资讯
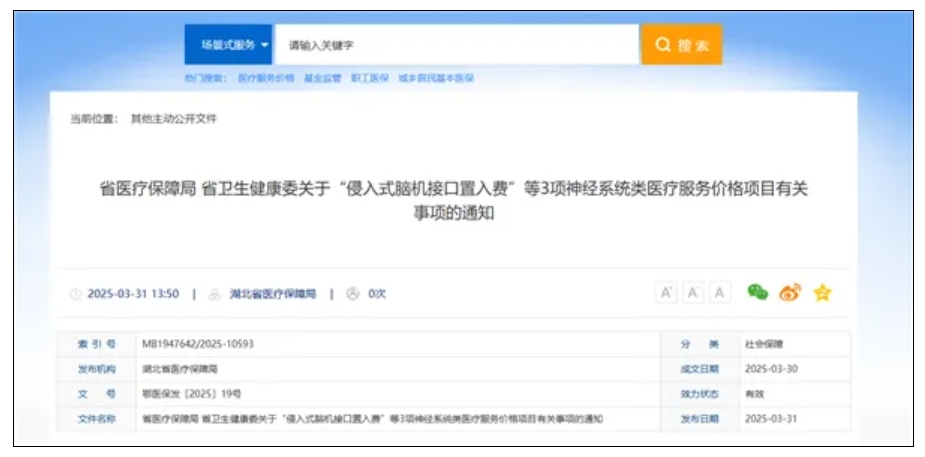
资讯 全国首个,湖北为脑机接口医疗服务定价
昨日(3月31日),据“湖北发布”消息,湖北省医保局发布全国首个脑机接口医疗服务价格,其中,侵入式脑机接口置入费6552元 次,侵入式脑机接口取出费3139元 次,非侵入式脑机...
2025-04-01 11:03
 资讯
资讯 一款国产创新流感药,获批
近日,据国家药监局官网信息显示,青峰医药下属子公司江西科睿药自主研发的1类创新药玛舒拉沙韦片(商品名:伊速达)正式获批上市,用于既往健康的12岁及以上青少年和成人单纯性...
2025-04-01 10:22
 资讯
资讯 26省联盟药品集采启动,聚焦妇科用药和造影剂
近日,山西省药械集中招标采购中心发布《关于做好二十六省联盟药品集中带量采购品种数据填报工作的通知》,开展相关采购数据填报工作。
2025-03-31 21:48
 资讯
资讯 优时比罗泽利昔珠单抗注射液(优迪革)中国获批,全球首个且唯一双亚型创新药治疗全身型重症肌无力
作为唯一人源化、高亲和力且具备创新修饰结构的IgG4单抗,关键Ⅲ期MycarinG试验证实罗泽利昔珠单抗注射液(优迪革®)较安慰剂显著改善全身型重症肌无力患者的多个临床终点与结局。
2025-03-31 15:58
 资讯
资讯 从手术麻醉到生命全周期护航,麻醉学科发展拓宽生命边界
3月26日,由中华医学会麻醉学分会、中国医师协会麻醉学医师分会等23家学协会共同举办的2025年中国麻醉周学术活动的启动仪式举办,该活动以“生命之重,大医精诚——守生命保驾护...
2025-03-31 15:30
 资讯
资讯 欧狄沃联合逸沃成为中国目前唯一获批的肝细胞癌一线双免疫联合疗法
欧狄沃联合逸沃对比仑伐替尼或索拉非尼,可显著改善不可切除肝细胞癌一线患者的总生存期(OS),客观缓解率(ORR)可改善近3倍,中位缓解持续时间(mDOR)达30个月
2025-03-31 13:45
 资讯
资讯 罗氏制药榜首 “现金牛” 产品罗可适(奥瑞利珠单抗)在华获批:开启多发性硬化症一年两次治疗新时代
罗氏制药今日(3月31日)宣布,其旗下创新药罗可适®(Ocrevus®,通用名:奥瑞利珠单抗注射液 ocrelizumab injection)正式获得中国国家药品监督管理局批准,每六个月静脉输...
2025-03-31 13:39
 资讯
资讯 三生有幸,医者仁心:三生制药向全体医药工作者致敬!
3月30日是国际医师节,由三生制药公益支持的以“三生有幸,医者仁心”为主题的公益活动,携手20位医生代表,以寄语海报的形式,共同向全体医护人员表达诚挚的祝福与关爱。
2025-03-30 17:38