
语音识别即通过麦克风捕捉用户发出的声音,将声波信号转换成机器可以处理的“发音特征”,再从发音和语言的“模型空间”中快速搜索最匹配的句子,即识别结果。语音识别过程就是一个模型匹配的过程,模型训练的好坏直接关系到系统识别的结果。
为了得到一个好的模型,往往需要有大量的原始语音数据来进行训练,特别是对于非特定人的语音识别系统来说,这一点显得更为重要。因此,在开始进行语音识别研究之前,首先要建立一个语音数据库。数据库包括不同性别、年龄、口音的说话人的声音,并且必须具有代表性,能均衡地反映实际使用情况。模型训练就是指按照一定的准则,从大量已知模式中获取表征该模式本质特征的模型参数。
目前在医学领域并没有专门的语音识别词库和模型。由于医学术语、药物名称、疾病名称等用词的专业性很强,识别率会大幅下降。我带领团队花费了7个月的时间,分别于iOS平台和Android平台,采用科大讯飞和云之声两个主流第三方SDK,对药品词库的36176个药品名称和疾病词库的23501个疾病名进行了测试,训练出错率较高的词汇,初步搭建了医学语音识别领域的第三方素材库,并决定免费开放给任何有志于开发移动医疗APP的创业团队和个人。
下面以Android为例,具体介绍我们构建体系的流程、标准和测试方法,以帮助各位移动医疗开发人员快速上手:
测试平台:2台android4.0系统手机(小米2、中兴U930HD)、珍立拍系统、科大讯飞SDK
小 组: A组和B组
测试方法:对所有药品和疾病名称进行反复测试,使用纠正训练法,来克服语音识别体系中HMM的训练效果。小组A测试药品,小组B测试疾病,普通话识别。
测试步骤:
1. 医学词汇约有数十万条,前期总结查找筛选最常用词汇并分组。
2. 使用珍立拍系统中的语音识别对所有词库进行第一遍测试。
3. 在第一遍测试的基础上,对筛选出来错误的词汇进行二次测试,再次筛选。
4. 总结出识别易错词汇,两组交叉测试后,随后交给程序人员,按科大讯飞SDK模型训练,输入相应代码,完善建库。

可能存在的影响因素:
1. 读错:由于医学词汇中有很多较为生僻的汉字,读错很难避免,很多医生即使会写这个词,但是发音也可能会错。
规避方法:遇到拿捏不准的汉字时,查找准确读音,尽量避免错误。
2. 环境因素:测试时,所处的环境存在噪音。
规避方法:选择在低噪音环境中测试,但不能完全于安静的环境中测试,因其与日常使用环境不符。
3. 汉字的同音字:例如“弱视”“荨麻疹”,识别结果“若是”“寻麻疹”。
4. 汉字尾音:例如“肝癌”,识别结果为“刚来”。
5. 实际发音影响:例如“阻生齿”,识别结果“主生殖”。
下面以疾病词汇举例:

测试小结:
由统计结果可以看出,疾病名的识别率高于药品名。笔者分析,造成此结果的原因在于,疾病名的广普率要高于药品名,所以各个语音识别公司比较重视,而且疾病生僻汉字较少,而药品种类要远多于疾病种类,其中生僻汉字也较多。二次测试的正确率较一次测试大约提升了一个百分点左右,还是可以适当减少错误数据库中的词汇量。
音节短的词出错率较高,如:单音节词,痣(识别结果“志”),双音节词,义眼(识别结果“一眼”),长音节词出错率低,原因可能是音节越短的词,其同音节的普通词较其更常见,而且如果其尾音特殊的话,影响较大。
针对医学专业词汇识别率低的问题,目前可使用以下三种解决办法:
一、 扩充自定义词库
虽然有用户词表,但是目前科大讯飞用户词表仅限数量2000,经沟通后他们正在扩大词汇表数量中。但如果数据过大,将会导致数据包过重的问题,而移动端由于存储和运算能力受限,所以无法满足数量庞大的整个医学词库,因此我们只能先做常用库。
二、 搭建第三方素材库
语音识别虽然在实用性上已得到很大提高,但是由于目前语音识别的单一性(只能单纯的识别中文或者英文),以及使用环境、语音差异化等因素的影响,容易造成识别错误。就这些因素而言,我们为此做了大量的基础工作,用于搭建第三方数据库,在尽可能排除其它干扰因素的情况下,检测出识别错误的词汇,也为下一步构建专业领域的识别模型搭建出了样本数据库(针对大量样本数据库,精简出识别错误的小样本数据库,减少模型训练词库)。
三、 构建专业领域的识别模型
对于有大量专业词汇的识别系统来说,使用模型训练可以有效提升识别率,目前模型训练比较常用的有四种方法:最大似然估计、纠正训练法、最小分类错误、最大互信息方法。模型训练需要专业的技术,并与语音识别公司进行合作,由企业提供词库信息和语音集,专业人员采用模型训练对需要识别的词库进行训练,最终给出个性化定制的识别模型,以提升识别率。
语音识别技术在移动医疗领域中的应用会越来越普遍,但还有大量的基础工作需要我们大家齐心协力去完成。希望业内的精英之士能够对此多交流,多合作,抛开一些利益的纠葛,共同为行业的发展贡献出自己的力量。
来源:健康界

为你推荐
 资讯
资讯 圣因生物完成超 1.1 亿美元 B 轮融资,加速 RNAi 疗法全球布局
本轮融资由知名产业机构领投,国际主权基金、中国生物制药、君联资本等十余家机构跟投,全球制药巨头礼来公司战略入局,高瓴创投、启明创投等现有股东持续加码支持,融资规模创...
2025-12-12 16:59


 资讯
资讯 投后估值达21.37亿元,实体瘤细胞治疗领军企业君赛生物递表港交所
君赛生物共有5款在研产品,其中核心产品也是进展最快的是GC101,正开展上市前的关键II期临床试验,有望成为国内首个获批上市的TIL细胞创新药
2025-12-12 09:24
 资讯
资讯 ESMO-IO | ORR达41.7%!君赛生物GC101 TIL治疗晚期后线非小细胞肺癌I期数据首次公布
这不仅是全球首个无需高强度清淋化疗、无需IL-2给药的TIL疗法治疗肺癌的临床研究,也是国内首个公开披露该领域数据的注册性临床研究。
2025-12-12 09:17
 资讯
资讯 君合盟生物启动重组 A 型肉毒毒素治疗成人上肢痉挛状态临床 III 期试验,并完成首例患者入组
该临床试验由复旦大学附属华山医院李放教授和上海市养志康复医院(即上海市阳光康复中心)靳令经教授联合牵头
2025-12-11 21:06
 资讯
资讯 Medidata发布全新调研报告:临床试验AI应用价值凸显,超七成用户反馈“达到或超预期”
基于对来自全球制药公司、生物科技公司及合同研究组织(CRO)中超200位核心决策者的深度调研,报告显示,目前AI在改善患者招募、优化数据管理、控制运营成本和提升试验效率等方...
2025-12-11 20:57
 资讯
资讯 近20年首个全新类别抗菌药物醋酸来法莫林纳入医保,开启中国成人社区获得性肺炎治疗普惠新篇章
该产品继2025年6月30日获得国家药品监督管理局批准用于治疗成人社区获得性肺炎(CAP)后又纳入国家医保目录
2025-12-11 20:50


 资讯
资讯 专注 “生物学 + AI” ,普瑞基准完成超亿元 D 轮融资,加速 AI 驱动新药研发
本轮融资由信立泰、广投资本、申宏中恒基金联合领投,老股东金谷汇枫、聚翊投资持续跟投
2025-12-10 15:55

 资讯
资讯 别把“嗜睡”当懒癌!新型促觉醒药翼朗清®获批,专注维持日间清醒
促觉醒药物翼朗清®(盐酸索安非托片)正式获得中国国家药品监督管理局(NMPA)批准,用于改善阻塞性睡眠呼吸暂停(OSA)伴有日间过度嗜睡(EDS)的成人患者的觉醒程度。
2025-12-10 11:04
 资讯
资讯 复星医药将其GLP-1产品全球化权益授权辉瑞,总里程碑付款近150亿人民币
12月9日晚间,复星医药发布公告称,公司控股子公司药友制药、复星医药产业与辉瑞共同签订《许可协议》,(其中主要包括)由药友制药就口服小分子胰高血糖素样肽-1受体(GLP-1R)...
2025-12-10 09:12


 资讯
资讯 Capricor Therapeutics公司宣布外泌体疗法Deramiocel在DMD三期中取得积极成果
近日,专注与外泌体疗法的Capricor Therapeutics(纳斯达克代码:CAPR)公司宣布其核心管线Deramiocel在杜氏肌营养不良症关键三期 HOPE-3 研究中取得积极成果。
2025-12-09 16:38

 资讯
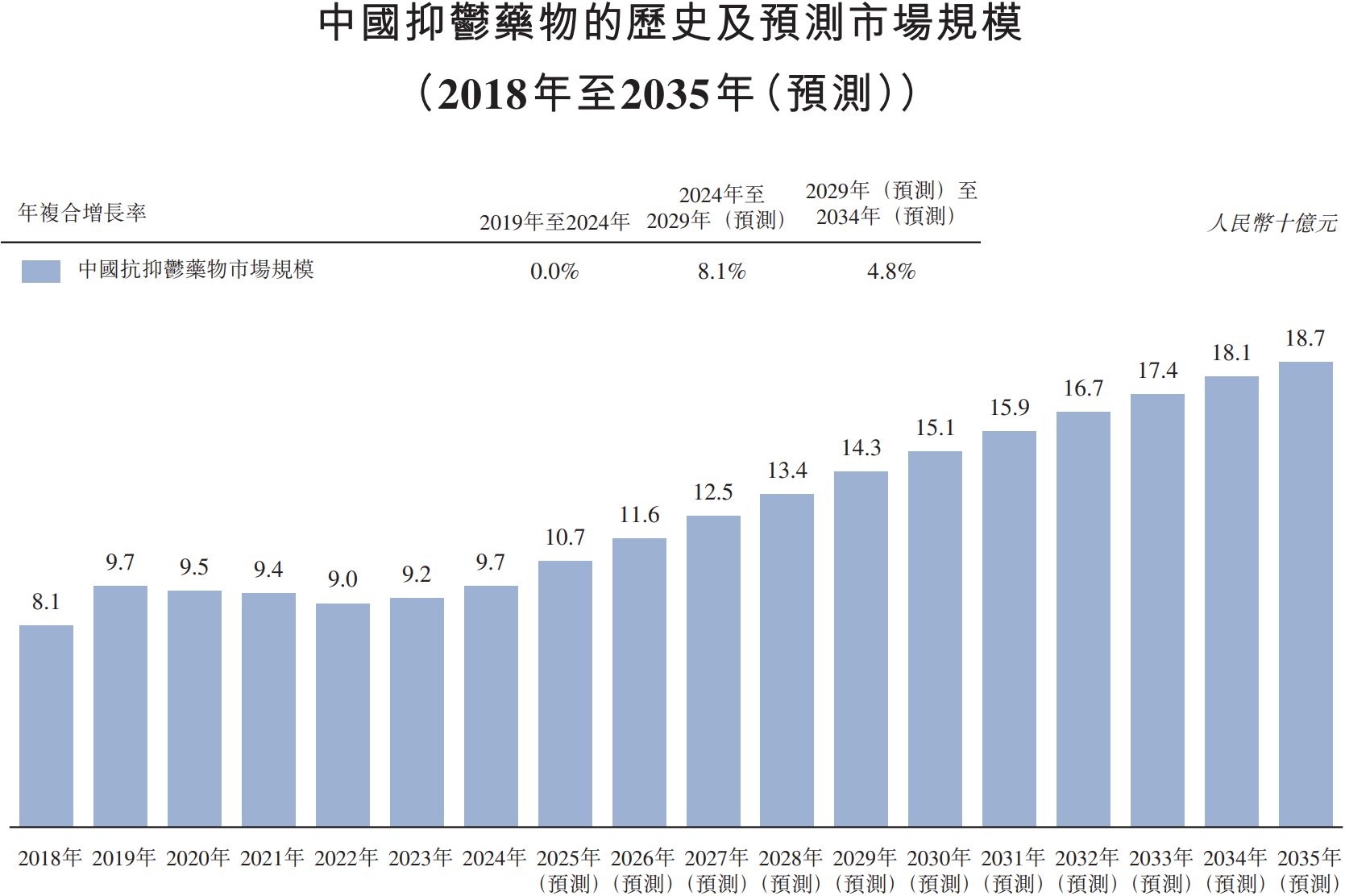
资讯 中药1类创新药剑指抑郁症治疗蓝海,远大医药GPN01360成功达到国内II期临床终点
国产抗抑郁症药物研发取得重大进展。近日,远大医药(0512 HK)的1 1类中药创新药GPN01360国内II期临床研究成功达到临床终点,产品表现出显
2025-12-08 18:27