
麻省沃尔瑟姆市(Waltham, Massachusetts)的一座钢筋混泥土建筑的二楼,一个实验室冰箱里的塑料盒中,包含着无数种化学分子。这些分子是葛兰素史克制药公司(Glaxo Smith Kline,GSK)合成的带DNA标签的分子,数目达到万亿种——这是银河系恒星数目的10倍。
各大制药公司和生物工程公司都在采用这种DNA编码分子库来迅速筛选能与疾病相关蛋白结合的分子,尤其是能与那些目前难以靶向的蛋白结合的药物。这种筛选方法比传统筛药方式更迅速,更便宜。基础科学研究者也可以使用这种方法来探索基本生物学问题,研究酶、受体和细胞通路。
药物研发的起始步骤往往是:研究人员合成大量化学分子,然后测试这些分子对目标蛋白的结合作用。在多孔板的每个孔里加入目标蛋白,然后分别加入各种药物分子,检测这些分子对蛋白活力的影响。这种方法被称为高通量筛选(high-throughout screening,HTS),主要使用机器自动测试上百万种化学分子,但仍然耗时耗力还费钱,而且不一定凑效。
过去几年来,药物化学家通过用DNA标记化学分子,形成分子的二维码,从而提高药物研发成功率。这些DNA编码分子库具有诸多优点:首先,研究者并不需要单独测试每种分子;而是只需把分子分成各种混合物,然后检测混合物是否对目标蛋白活性有影响。一旦有分子能与目标蛋白结合,它就很容易被认出来——因为可以检测它的DNA二维码。
1992年斯克里普斯研究所(Scripps Research Institute)的分子生物学家Sydney Brenner 和化学家 Richard Lerner首次提出DNA编码分子库这一概念。此后,DNA编码分子库一直发展迅猛。2007年,GSK公司以5500万美金收购了一家在DNA标签分子库研究站处于领先地位的公司。瑞士巴塞尔的诺华公司和罗氏公司也建立了内部DNA标签分子库研究项目。多家新兴生物科技公司——包括沃尔瑟姆的X-chem、哥本哈根的Vipergen、剑桥的Ensemble制药公司和瑞士的Philochem——也和学界和工业界合作,迫切希望使用该技术。
“人们现在明白了,DNA编码分子库不是一种时尚,而是可以实现的。” 波士顿阿斯利康公司(X-Chem公司的合作者之一)化学创新中心的执行理事Robert Goodnow这样说到。
DNA编码分子库不会取代高通量筛选:由于一些化合物不能使用DNA编码技术合成,各大公司已在高通量筛选上投入巨资。但DNA编码分子库提供了一个快速有效、低成本的互补方案,帮助寻找与新的或具有挑战性的目标蛋白结合的分子。例如,寻找泛素连接酶——一种将泛素分子连接到目标蛋白的酶、可作为癌症治疗的靶向分子——的结合分子。

图:建立DNA二维码
大即是美
GSK目前拥有世界上最大的DNA编码分子库:GSK的高通量筛选库有200万种分子,而DNA编码分子库有1万亿种分子,是高通量筛选库的50万倍。
建立DNA编码库有几种方式:最大的分子库,如GSK公司,使用 DNA记录法(图:建立DNA二维码)。首先合成化学构建模块,如氨基酸、胺和羧酸,然后通过化学反应,为它们添加不同的DNA二维码。将第二个建构模块加入到混合物中,形成新的小分子,DNA标签延长。通过连接4个构建模块,化学家可创造药物分子。由于建筑模块的种类有上千种,因此潜在的组合数目非常巨大。
与传统高通量筛选相比,化学家必须单独对每个化合物进行检测,而DNA编码库更易于维护和使用。DNA编码库可以存储在一个单一测试管中,而高通量筛选需要使用机器人把每个分子单独放到一个测试管中。
但GSK的经理Chris Arico-Muendel表示,DNA编码库最大的优点,是可合成的分子数量多。对于新或难的目标蛋白,GSK使用DNA编码库和高通量筛选的频率相同,甚至更高。迄今为止,GSK公司使用DNA编码技术合成的最先进的化合物是GSK2256294,能有效阻断环氧化物酶,一种参与脂肪分解的酶。该候选药物是Praecis和GSK的合作成果,已通过1期临床安全实验,将进一步评估其在糖尿病、伤口愈合和慢性阻塞性肺病的治疗中的效果。Arico-Muendel表示,他们很高兴,GSK的DNA编码库能发展这么顺利。
随着化学构建模块的增多,以及连接方式的增多,DNA编码库还会进一步扩大。
X-Chem首席执行官Richard Wagner则认为,在不久的将来,DNA编码库不仅变得更大,也能更快进入临床。传统的药物筛选中,药物化学家有时要花许多年来调整化合物结构,让它们更特异、强效和安全。Wagner表示,可以说,传统筛药只是一场概率游戏。相比之下,基因编码库的大尺寸意味着,按照概率计算,一些化合物更易进入临床。尽管这些化合物仍然需要优化,但更接近理想分子,需要调整的幅度更小。
X-Chem的DNA编码库有1200亿种化合物,并已开始进行实践。仅仅过了一年,他们就筛选出了最先进的候选药物——一种autotaxin抑制剂,能阻断一种磷脂转化成另一种磷脂。X-Chem的子公司X-Rx现在计划在2017年开始纤维变性药物的临床试验。业界对X-Chem的DNA编码分子库的兴趣日益高涨:在过去五年中,该公司已与几大制药巨头,包括罗氏、阿斯利康、拜耳、强生、辉瑞、赛诺菲等签署合作协议,此外还和多个生物工程公司和学术实验室建立合作。
定制合成
其他生物公司则采用另一种方法合成分子库。他们不仅使用DNA标签来标记分子,也使用DNA标签作为合成模板。哈佛大学(Harvard University)的化学家David Liu和他的学生开发了一种DNA模板法,产生环形分子库。环状分子更大、更稳定,能在多个位点与目标分子结合,增强结合反应的特异性。(GSK和X-Chem公司都有很大的DNA编码环形分子库。)
Liu首先产生单链DNA模板,模板包含与化学构建模块的DNA标签互补的序列。然后依次往化学反应容器中加入DNA标记的化学构建模块,依靠DNA碱基配对,使各个构建模块的DNA标签与DNA模板结合。最后的反应是将各个化学构建模块连接成环状,产生环形分子和一个长链DNA标签。
构建DNA模板库需要大量工作,因为研究人员必须为每个分子设计模板,还需要为成千上万种化学构建模块设计DNA标签。因此,DNA模板法产生的分子库小于DNA记录法产生的分子库,但依旧远大于高通量筛选库,并且还拥有其他优点。在DNA模板法中,科学家们一开始就知道最终合成的分子有哪些,他们可以纯化分子库,去掉那些标签错误的分子。这增加了筛药的成功率。相比之下,巨大的DNA记录分子库可能仍然包含标签错误的化合物。万一标签错误的分子与目标蛋白结合,研究者们就需要浪费大段时间在纠错上。
Liu的分子库包含14000种分子,目前已取得一些成功。2014年,他的团队报道,他们发现了一种稳定的、特异的胰岛素降解酶(insulin-degrading enzyme, IDE,与2型糖尿病有关)小分子抑制剂,在此之前,研究者们花了几十年寻找和设计IDE抑制剂。Liu等人开始研究IDE在健康和疾病中的作用,帮助寻找其它IDE抑制剂。目前他们正努力把小分子抑制剂转化成临床药物。
Liu也筛选了100多种目标蛋白的抑制剂。这些蛋白大多急需小分子抑制剂,来促进相关领域的研究。“我没有想到,第一代分子库在7年后的今天,仍然能为我们带来这么多科学发现。在筛选抑制剂上,我们成果累累。到现在为止,我们发现了非常多种分子的抑制剂,数目多到我们无法一一研究。”
尽管如此,Liu仍然不懈发展第二代DNA模板分子库,这个分子库包含256000个环形分子。Liu在2004年创立了Ensemble Therapeutics公司,该公司的分子库现在已有1000万个分子。公司聚焦于寻找免疫检查点蛋白的抑制剂,调节免疫系统和泛素连接酶。他还授权给诺华公司,开发靶向炎症相关蛋白白细胞介素-17的药物。
快速筛选
一旦分子库建立成功,就开始了目标蛋白结合分子的寻找之旅。大多数研究人员依靠“亲和筛选”来找出这些化合物。为此,他们为靶蛋白添加纯化标签,使用纯化标签把结合了分子的蛋白提取出来。最后一步是读取DNA标签,鉴别与蛋白结合的小分子。
这种方法的一个优点是,仅需一点点目标蛋白,就能得到结果。在一个项目中,Arico-Muendel想寻找一种不稳定的、获取量很少的蛋白的结合分子。他说,“把蛋白放在干冰上过夜后,我们很快完成了整个筛选过程。而且我们找到了一些能与该蛋白结合的分子。”高通量筛选是无法完成这种这类实验。因为高通量筛选里,目标蛋白必须稳定且足量,且要在实验开始前往千百个孔里加入目标蛋白。
但亲和筛选也有其不足。笨重的DNA标签有时会阻碍分子与目标蛋白的互动,因此一些有效的分子可能被遗漏。但由于DNA编码库太大,研究者们通常不太在意这些损失。更大的问题是,小分子和标签可以结合到纯化柱上,产生假阳性率。纯化标签也会影响目标蛋白的结构,引入数据误差。
几个研究小组已经找到了解决之道。Vipergen,一家拥有5000万个分子的DNA模板库的生物技术公司,采用“粘合剂陷阱”来解决这个问题。
Vipergen公司的首席执行官Nils Hansen表示,你可以冻结你的蛋白——分子库混合物,切割成非常小的冰块。如果冰块足够小,每个冰块只包含一个靶蛋白。在这个尺度上,即使没有纯化,与该靶蛋白结合的小分子的比例也会增加。Vipergen在水和油乳剂中完成筛选,也能达到同样的效果。此时,微小的水滴的效果等同于小冰块。Hansen感慨,“这超酷!”
目前,DNA编码分子库最适合用于筛选可溶于水、自由浮动的蛋白的抑制剂。但很多重要的药物靶点嵌于细胞表面,因此不可能使用传统的亲和筛选法。例如,大约40%的经认证药物的靶点都是细胞膜上感受胞外刺激的G蛋白偶联受体。Goodnow指出,膜结合蛋白的筛选技术在不断发展,“但仍然不够完善”。
一种解决方法是混合DNA编码分子库与过表达膜结合蛋白靶标的完整细胞。小分子可以与细胞表面的目标蛋白结合。然后,研究者洗去未发生结合的分子,加热细胞,读取DNA标签,鉴定有效的小分子。GSK已经用这种方法来确定一个受体——该受体在精神分裂症和中枢神经系统疾病中起重要作用的强效抑制剂。
X-Chem也在膜结合蛋白药物筛选中获得成功。Wagner说,“以前,我们主要筛选可溶性蛋白的抑制剂。但数据显示,我们现在也能筛选相对困难的膜结合蛋白的抑制剂。” Wagner补充说,随着DNA编码库的不断扩大,以及新的筛选方法的问世,“DNA编码库将成为医药行业药物研发的支柱之一。”
来源:生命奥秘

为你推荐
 资讯
资讯 悦唯医疗完成近亿元A++轮投资,加速重症冠心病诊疗全流程创新器械研发与国产替代
此次融资将主要用于深化冠心病诊疗全流程创新器械和脉动式左心室辅助系统等新产品的研发,以及加速已获准上市的心脏稳定器等产品的市场推广。
2025-04-03 09:28
 资讯
资讯 海尔盈康一生启动孤独症儿童关爱行动,创新罕见病可持续公益新生态
本次活动聚焦孤独症儿童的诊疗,探讨交流AI赋能全流程防治康体系创新、前沿性生物科技诊疗技术等话题,旨在通过生态联盟的力量推动医学研究、科技创新与人文关怀的融合,让“星...
2025-04-03 09:11

 资讯
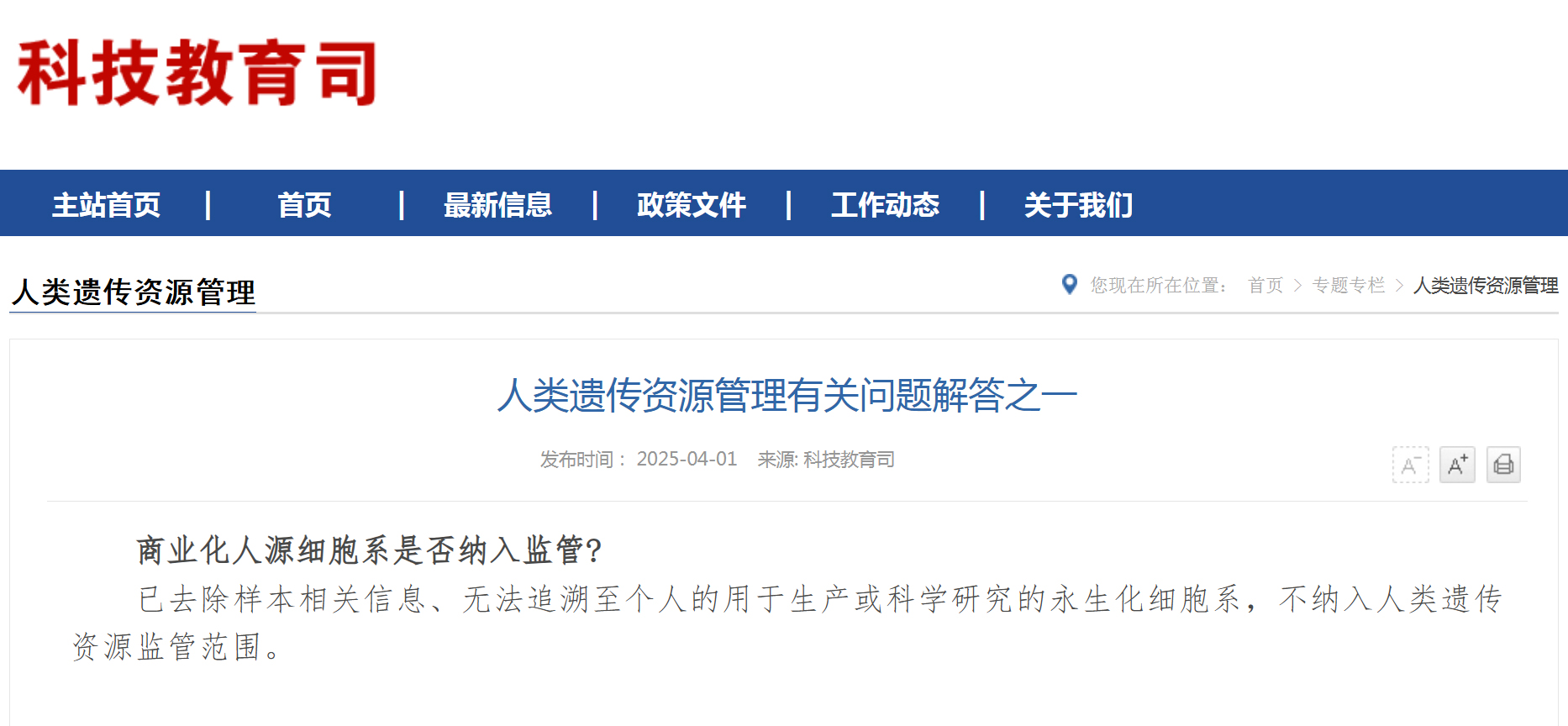
资讯 《NPJ digital medicine》刊发李冬梅教授团队成果:AI赋能高效识别眼睑肿物
亚太眼整形外科学会主席、中华医学会眼科分会眼整形眼眶病学组副组长李冬梅教授团队携手爱尔数字眼科研究所,在《NPJ digital medicine》(影响因子:12 4)学术期刊发表团队...
文/李林 2025-04-02 10:27

 资讯
资讯 默克全球执行副总裁周虹:合作与创新是默克未来五年战略的两大关键词
近日,德国默克医药健康全球执行副总裁、中国及国际市场负责人周虹带领医药健康中国及国际市场管理团队开启了2025年度首次“中国行”。
2025-04-01 17:11
 资讯
资讯 首个且唯一,阿斯利康PD-L1单抗获FDA批准治疗肌层浸润性膀胱癌
度伐利尤单抗联合吉西他滨和顺铂作为新辅助治疗,随后度伐利尤单抗作为根治性膀胱切除术后的辅助单药治疗,用于治疗肌层浸润性膀胱癌成年患者。
2025-04-01 14:37
 资讯
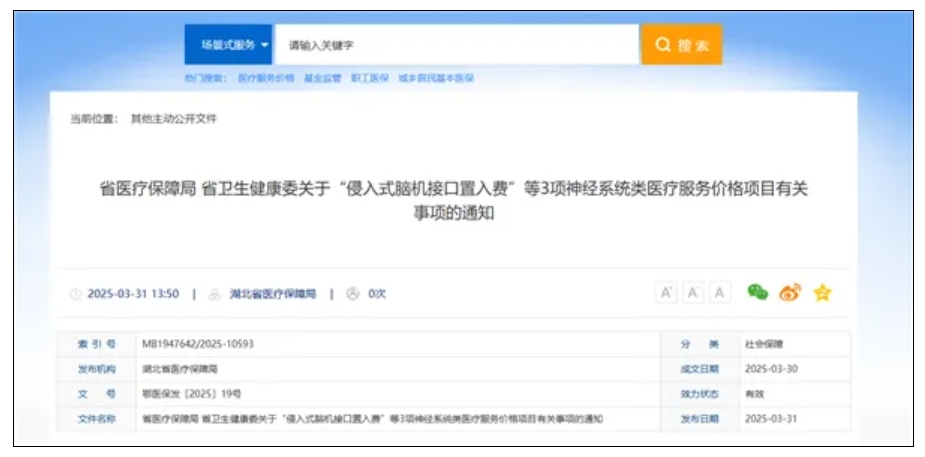
资讯 全国首个,湖北为脑机接口医疗服务定价
昨日(3月31日),据“湖北发布”消息,湖北省医保局发布全国首个脑机接口医疗服务价格,其中,侵入式脑机接口置入费6552元 次,侵入式脑机接口取出费3139元 次,非侵入式脑机...
2025-04-01 11:03
 资讯
资讯 一款国产创新流感药,获批
近日,据国家药监局官网信息显示,青峰医药下属子公司江西科睿药自主研发的1类创新药玛舒拉沙韦片(商品名:伊速达)正式获批上市,用于既往健康的12岁及以上青少年和成人单纯性...
2025-04-01 10:22
 资讯
资讯 26省联盟药品集采启动,聚焦妇科用药和造影剂
近日,山西省药械集中招标采购中心发布《关于做好二十六省联盟药品集中带量采购品种数据填报工作的通知》,开展相关采购数据填报工作。
2025-03-31 21:48
 资讯
资讯 优时比罗泽利昔珠单抗注射液(优迪革)中国获批,全球首个且唯一双亚型创新药治疗全身型重症肌无力
作为唯一人源化、高亲和力且具备创新修饰结构的IgG4单抗,关键Ⅲ期MycarinG试验证实罗泽利昔珠单抗注射液(优迪革®)较安慰剂显著改善全身型重症肌无力患者的多个临床终点与结局。
2025-03-31 15:58
 资讯
资讯 从手术麻醉到生命全周期护航,麻醉学科发展拓宽生命边界
3月26日,由中华医学会麻醉学分会、中国医师协会麻醉学医师分会等23家学协会共同举办的2025年中国麻醉周学术活动的启动仪式举办,该活动以“生命之重,大医精诚——守生命保驾护...
2025-03-31 15:30
 资讯
资讯 欧狄沃联合逸沃成为中国目前唯一获批的肝细胞癌一线双免疫联合疗法
欧狄沃联合逸沃对比仑伐替尼或索拉非尼,可显著改善不可切除肝细胞癌一线患者的总生存期(OS),客观缓解率(ORR)可改善近3倍,中位缓解持续时间(mDOR)达30个月
2025-03-31 13:45
 资讯
资讯 罗氏制药榜首 “现金牛” 产品罗可适(奥瑞利珠单抗)在华获批:开启多发性硬化症一年两次治疗新时代
罗氏制药今日(3月31日)宣布,其旗下创新药罗可适®(Ocrevus®,通用名:奥瑞利珠单抗注射液 ocrelizumab injection)正式获得中国国家药品监督管理局批准,每六个月静脉输...
2025-03-31 13:39
 资讯
资讯 三生有幸,医者仁心:三生制药向全体医药工作者致敬!
3月30日是国际医师节,由三生制药公益支持的以“三生有幸,医者仁心”为主题的公益活动,携手20位医生代表,以寄语海报的形式,共同向全体医护人员表达诚挚的祝福与关爱。
2025-03-30 17:38